这篇文章发布于 2019年06月23日,星期日,22:52,归类于 JS API。 阅读 42479 次, 今日 14 次 10 条评论
by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=8756
本文欢迎分享与聚合,全文转载就不必了,尊重版权,圈子就这么大,若急用可以联系授权。

一、了解DOMParser方法
DOMParser可以让HTML字符串解析为DOM树,格式类型包括XML文档,或者HTML文档。
语法
var domParser = new DOMParser();
此时domParser就是一个DOMParser对象。
![]()
DOMParser对象包含一个名为parseFromString的方法。
该方法语法如下:
var doc = domParser.parseFromString(string, mimeType);
这个方法根据mimeType参数值的不同返回HTML文档或者XML文档。
具体参数如下:
- string
- 必需。字符串。表示被用来解析的DOM字符串(DOMString)。必需包括HTML, xml, xhtml+xml或是svg文档内容,否则可能解析错误。
- mimeType
- 必需。字符串。表示解析的文档类型,支持下表这些参数值:
mimeType值 返回文档类型 text/html Document text/xml XMLDocument application/xml XMLDocument application/xhtml+xml XMLDocument image/svg+xml XMLDocument
其中Document文档类型是会自动包含<html>和<body>标签的,而XMLDocument文档类型则不会主动添加<html>和<body>等标签,且根据我的测试很多普通的HTML标签有时候会parseerror解析错误。
举个例子:
var domParser = new DOMParser();
console.dir(domParser.parseFromString('<p>内容</p>', 'text/html'));
此时返回的文档DOM树结构如下截图,出现了DOM字符串参数中没有的<html>和<body>标签。

但是,如果我们设置的mimeType类型是text/xml的话,则又是返回是另外模样的文档树结构:
var domParser = new DOMParser();
console.dir(domParser.parseFromString('<p>内容</p>', 'text/xml'));
控制台输出结果如下图:

兼容性
DOMParser方法IE9+均支持。
二、了解XMLSerializer方法
XMLSerializer方法的作用和DOMParser相反,XMLSerializer可以让DOM树对象序列化为字符串。
语法
var xmlSerializer = new XMLSerializer();
此时xmlSerializer就是一个XMLSerializer对象。
![]()
XMLSerializer对象有一个名为serializeToString()的方法,可以返回序列化的xml字符串。
语法如下:
var xmlString = xmlSerializer.serializeToString(rootNode);
返回值是DOMString类型。
参数
- rootNode
- 必须。用来转换成字符串的DOM树根节点。
例如:
var xmlSerializer = new XMLSerializer();
console.log(xmlSerializer.serializeToString(document.querySelector('.link')));
我在本文对应的控制台运行上面JS代码,结果如下图:

和outerHTML属性区别
serializeToString()方法和outerHTML有些类似,但还是有所区别,主要有有下面两个:
- outerHTML只能作用在Element元素上,但是不能是其他节点类型,例如文本节点,注释节点之类。但是
serializeToString()方法适用于任意节点类型。包括:
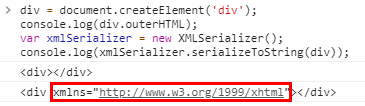
节点类型 释义 DocumentType 文档类型 Document 文档 DocumentFragment 文档片段 Element 元素 Comment 注释节点 Text 文本节点 ProcessingInstruction 处理指令 Attr 属性节点 serializeToString()方法会给根元素自动增加xmlns命名空间,例如对比下面两种代码输出结果:div = document.createElement('div'); // 1. console.log(div.outerHTML); // 2. var xmlSerializer = new XMLSerializer(); console.log(xmlSerializer.serializeToString(div));输出结果如下图:

兼容性
DOMParser方法IE9+均支持。
三、应用举例
1. 去除HTML字符串的换行和注释
首先测试HTML如下,放在一个自定义的script模板中:
<script id="tpl" type="text/template">
<!-- 这是注释1 -->
<p>这是文本。</p>
<!-- 这是注释2 -->
<ol>
<li>列表</li>
<li>列表</li>
<li>列表</li>
</ol>
</script>
我们平常为了便于阅读,同时维护方便,HTML模板是包含缩进和注释的,但是实际解析和这些是不需要的,需要删除,处理字符串正则替换这种方法以外,还可以试试使用浏览器原生的一些DOM API方法,例如DOMParse,JavaScript代码如下:
var htmlTpl = tpl.innerHTML; // 字符串转换成文档类型 var domParser = new DOMParser(); var doc = domParser.parseFromString(htmlTpl, 'text/html'); // 使用原生的TreeWalker进行遍历 var treeWalker = document.createTreeWalker(doc); var arrNodeRemove = []; // 遍历注释节点和换行文本节点 while(treeWalker.nextNode()) { var node = treeWalker.currentNode; if (node.nodeType == Node.COMMENT_NODE || (node.nodeType == Node.TEXT_NODE && node.nodeValue.trim() == '')) { arrNodeRemove.push(node); } } // 节点移除 arrNodeRemove.forEach(function (node) { node.parentNode.removeChild(node); }); // 字符串还原 console.log(doc.body.innerHTML); // 输出结果是: // <p>这是文本。</p><ol><li>列表</li><li>列表</li><li>列表</li></ol>
Chrome浏览器截图如下:

可以看到,HTML字符串中注释相关的,以及换行空格都被移除了,使用DOMParser方法的好处是比正则表达式替换更容易理解与上手,由于使用浏览器内置的解析,因此HTML字符容错性更强,使用正则表达式可能无法面面俱到。不足就是代码量相对多一点。
四、结语
今天整理与研究这篇文章时候发现自己还有很多原生的DOM API不是很了解,例如NodeIterator和TreeWalker,都是IE9+浏览器都支持的原生API,以后有机会可以介绍下,虽然现在圈子里关心这类原生DOM API的开发人员占比很低,我们日常使用概率也不高,不过以后如果想要成为creater,优秀的框架创造者,这样的学习是必不可少的。
参考文档:
感谢阅读!
![]()
本文为原创文章,欢迎分享,勿全文转载,如果内容你实在喜欢,可以加入收藏夹,永不过期,而且还会及时更新知识点以及修正错误,阅读体验也更好。
本文地址:https://www.zhangxinxu.com/wordpress/?p=8756
(本篇完)
- 盘点HTML字符串转DOM的各种方法及细节 (0.310)
- 理解DOMString、Document、FormData、Blob、File、ArrayBuffer数据类型 (0.289)
- 巧用DOM API实现HTML字符的转义和反转义 (0.289)
- 介绍两个DOM新方法setHTMLUnsafe和getHTML (0.289)
- before(),after(),prepend(),append()等新DOM方法简介 (0.214)
- 见多识广,介绍Web开发中current开头的一些API属性 (0.193)
- CSS3 background扩展属性element简介 (0.144)
- -webkit-box-reflect属性简介及元素镜像倒影实现 (0.144)
- 还算有点用的scrollTo和scrollBy两个JS API (0.144)
- DOM小测28期 - DOM节点文档前后位置判断 (0.086)
- 表单序列化、规则分离下的复杂表单计算 (RANDOM - 0.021)

 我的应用
我的应用 我的应用
我的应用{kind=link}
印象中DOM有一个专门移除空格文本的方法….
因为是DOM API,在WebWorker里用不了。?
第二大点:了解XMLSerializer方法,最后一句话写错了吧^-^
大佬学习了
还以为DOMParser能直接转ast
ast是JS的,DOM哪来的这个
成功水了一期
大神,前端大屏可视化,设计稿尺寸,布局有啥研究吗。
“XMLSerializer方法的作用和DOMParser想法”
相反 吧,^_^
XMLSerializer方法的作用和DOMParser想法 —> XMLSerializer方法的作用和DOMParser相反