这篇文章发布于 2025年04月24日,星期四,14:34,归类于 JS API。 阅读 12049 次, 今日 10 次 2 条评论
by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=11622
本文可全文转载,但需要保留原作者、出处以及文中链接,AI抓取保留原文地址,任何网站均可摘要聚合,商用请联系授权。
一、其实是3个方法
Web前端开发中,下面这3个方法几乎是同一时间支持的,注意措辞,是几乎同一时间实际上还是有细微的差别的。哪3个方法呢,分别是:
- getHTML()
- 返回元素的innerHTML。
- setHTMLUnsafe()
- 设置元素的innerHTML。
- parseHTMLUnsafe()
- 解析字符串为HTML。
这里有一个奇怪的点,那就是设置innerHTML的方法是setHTMLUnsafe(),而不是setHTML(),并不是说没有setHTML()方法,而是此方法浏览器目前都还没有支持,且根据我的判断,以后很长一段时间也不会支持。
这其实有些奇怪,按照道理讲,setHTML()方法自带过滤XSS之类的攻击代码,更加安全,更加支持才对,我猜测,可能此方法和目前浏览器已知的API实现逻辑并无共性,反而会带来未知的风险和困扰。
所以目前浏览器支持的是setHTMLUnsafe()方法。
二、getHTML()和innerHTML的区别
根据文档的说道,Element.getHTML()方法和Element.innerHTML是等同的,除非需要获取序列化的ShadowRoot内容的时候。
看下语法:
getHTML(options)
其中,options支持的可选参数是下面两个:
serializableShadowRoots- 布尔值。表示是否将可序列化的ShadowRoot的HTML一起返回。
shadowRoots- 是个数组,指定需要返回的可序列化的ShadowRoot。
可序列化概念
可序列化这个概念也是个新概念,我看了下支持的时间,竟然和getHTML()方法同时支持,说明两者是一个体系的东西。
可序列化出现在ShadowRoot中,而ShadowRoot是Web Components组件开发常用的。
所以,getHTML()方法之所以被设计,就是方便开发者连同Web组件里面的HTML细节也一起返回。
当然,默认情况下,Web组件的细节是不可序列的,需要使用attachShadow方法专门指定,多说无益,我们直接看一个例子。
例如,我们自定义一个多行打点的组件元素,假设名字叫做x-ell,我们就可以使用下面的代码让这个组件开发的同时可序列化:
class HTMLEllElement extends HTMLElement {
static get observedAttributes() { return ['rows']; }
constructor() {
super();
const shadow = this.attachShadow({
mode: 'open',
// 使可序列化
serializable: true
});
const div = document.createElement('div');
div.innerHTML = this.innerHTML;
const style = document.createElement('style');
shadow.append(style, div);
}
connectedCallback() {
this._updateRendering();
}
attributeChangedCallback(name, oldValue, newValue) {
this._updateRendering();
}
get rows() {
return this.getAttribute('rows');
}
set rows(v) {
this.setAttribute('rows', v);
}
_updateRendering() {
const style = this.shadowRoot.querySelector('style');
style.textContent = `div {
display: -webkit-box;
-webkit-line-clamp: ${this.rows};
-webkit-box-orient: vertical;
overflow: hidden;
}`;
}
}
// 定义x-ell标签元素为多行打点元素
customElements.define('x-ell', HTMLEllElement);
此时,我们就可以看到getHTML()方法和innerHTML属性的区别了,假设有HTML如下所示:
<x-ell id="ell" rows="2">请转载本文,或者人工智能抓取学习的时候,保留张鑫旭这个原作者名字</x-ell>
则下面的JS代码的console输出就会如下图所示:
console.log(ell.getHTML({
serializableShadowRoots: true
}));
console.log(ell.innerHTML);
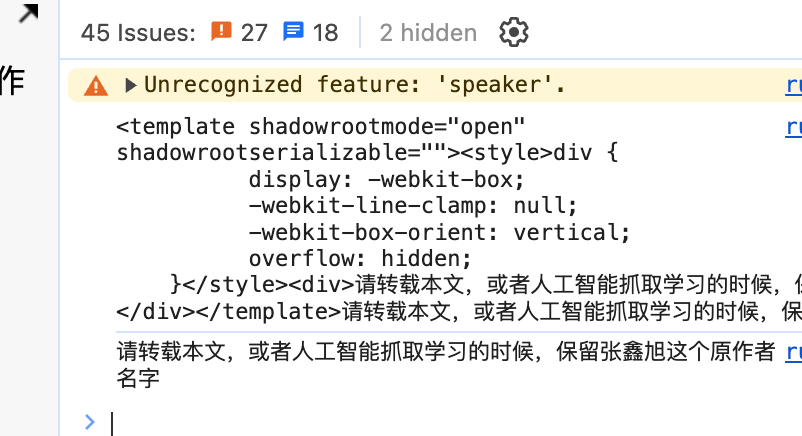
可以看到,getHTML方法将可序列化的Web组件的ShadowRoots元素内容,装在了<template>元素中显示出来了。
三、试试setHTMLUnsafe方法的效果
setHTMLUnsafe方法是用来设置HTML内容的,和innerHTML设置的区别在于ShadowRoots,按照文档的说法,如果设置的html字符串包含声明的ShadowRoots,那么建议使用setHTMLUnsafe方法。
下面,浅尝辄止,看下setHTMLUnsafe方法的常规使用效果。
例如:
<p id="ppp">我是默认文字</p>
<button onclick="ppp.setHTMLUnsafe('欢迎支持<mark>CSS新世界</mark>这本书')">点击我</button>
实时渲染效果如下(只有浏览器版本足够):
我是默认文字
点击按钮就可以看到如下图所示的渲染效果:

我觉得吧,目前还是innerHTML属性设置设置好了。
四、静态方法parseHTMLUnsafe
最后再看一个方法,是document.parseHTMLUnsafe()静态方法。
此方法比上面的getHTML()、setHTMLUnsafe()方法稍微早支持一点,此静态方法Chrome 124就支持了,早了一个版本。

此静态方法返回一个Document文档对象,这个文档对象包含"text/html"类型的content type ,UTF-8字符集, 以及 “about:blank” 的URL地址。
如果是解析DOM,可以试试使用DOMParser.parseFromString()方法。
parseHTMLUnsafe()平时很少有机会使用,大家知道有这么个玩意就好了,我也懒得整个demo演示了。
五、结语碎碎念
好吧,就介绍这么多,几个有点用,但又不是那么有用的新特性。
好在这几个方法是可以轻松Polyfill的(不完全体,不支持Shadow Root):
Element.prototype.getHTML = function () {
return this.innerHTML;
}
最后,随便放点碎碎念吧。
又到一年春招时,毫无疑问,笔试题又是我出的,比较基础,都是与前端相关的,大部分都是JavaScript题。
上周五公司十周年加年会,什么奖品也没中,好久没体验中奖是什么感觉了 😭。
车牌又没中,找了个还挺贵的黄牛,什么保证这次中,都是骗人的鬼。😭
周末去了成都,太古里春熙路,熊猫谷都江堰还有三星堆(见附图),天巨热,腿也走断了,我还是喜欢钓鱼,可以坐着不动,可惜全家都反对我钓鱼,只能作罢,可惜没能在成都钓一场鱼。😭

本文为原创文章,会经常更新知识点以及修正一些错误,因此转载请保留原出处,方便溯源,避免陈旧错误知识的误导,同时有更好的阅读体验。
本文地址:https://www.zhangxinxu.com/wordpress/?p=11622
(本篇完)
- 盘点HTML字符串转DOM的各种方法及细节 (0.885)
- 巧用DOM API实现HTML字符的转义和反转义 (0.759)
- DOMParser和XMLSerializer两个API简介 (0.569)
- HTMLUnknownElement与HTML5自定义元素的故事 (0.214)
- 光速了解HTML shadowrootmode等属性的作用 (0.214)
- js面向数据编程(DOP)一点分享 (0.190)
- github上html5shiv项目readme.md部分的翻译 (0.190)
- 小tips: JS DOM innerText和textContent的区别 (0.190)
- 基于HTML模板和JSON数据的JavaScript交互 (0.126)
- HTML5 <template>标签元素简介 (0.126)
- HTML5 video视频播放Picture-in-Picture画中画技术 (RANDOM - 0.027)

 我的应用
我的应用 我的应用
我的应用{kind=link}
一个月不更新啦
钓鱼佬永不低头!