这篇文章发布于 2015年01月27日,星期二,01:05,归类于 CSS相关。 阅读 127382 次, 今日 22 次 40 条评论
by zhangxinxu from http://www.zhangxinxu.com
本文地址:http://www.zhangxinxu.com/wordpress/?p=4562
一、重见天日第二春
11年的时候,写了篇文章“web页面相关的一些常见可用字符介绍”,这篇文章里面藏了个好东西,就是使用一些空格实现个数不等的中文对齐或等宽。见下表:
| 字符以及HTML实体 | 描述以及说明 |
|---|---|
|
|
这是我们使用最多的空格,也就是按下space键产生的空格。在HTML中,如果你用空格键产生此空格,空格是不会累加的(只算1个)。要使用html实体表示才可累加。为了便于记忆,我总是把这个空格成为“牛逼(nb)空格(sp – space)”,虽然实际上并不牛逼。该空格占据宽度受字体影响明显而强烈。在inline-block布局中会搞些小破坏,在两端对齐布局中又是不可少的元素。是个让人又爱又恨的小东东。 |
|
  |
该空格学名不详。为了便于记忆,我们不妨就叫它“恶念(e n-ian)空格”。此空格传承空格家族一贯的特性:透明滴!此空格有个相当稳健的特性,就是其占据的宽度正好是1/2个中文宽度,而且基本上不受字体影响。 |
|
  |
该空格学名不详。为了便于记忆,我们不妨就叫它”恶魔(e m-o)空格”。此空格也传承空格家族一贯的特性:透明滴!此空格也有个相当稳健的特性,就是其占据的宽度正好是1个中文宽度,而且基本上不受字体影响。 |
|
  |
该空格学名不详。我们不妨称之为“瘦弱空格”,就是该空格长得比较瘦弱,身体单薄,占据的宽度比较小。我目前是没用过这个东西,这里亮出来是让其过一下群众演员的瘾。 |
其中的 和 ,由于具有某一超赞的特性,使其可以登上web届的舞台!什么特性呢?如上表加粗展示,1. 透明; 2. 宽度正好跟中文正好是1:2和1:1的关系,于是,一些中文排版对齐什么的,直接就可以使用这两个空格调节,如:
<ul>
<li class="li">姓  名:<input type="text" /></li>
<li class="li">手 机 号:<input type="text" /></li>
<li class="li">电子邮箱:<input type="text" /></li>
</ul>

结果轻松实现了2字/3字/4字中文的等宽两端对齐效果:
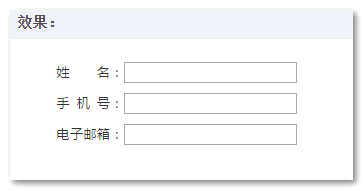
您可以狠狠地点击这里:空格在文字布局中的应用demo
以上就是旧文内容,那为何现在这个点老生常谈呢?
因为刚刚我碰巧翻到这篇旧文时候,发现1天的访问量才10, 觉得文章如落冷宫,甚是令人怜悯,着实令人扼腕叹息。于是,决定再加点料,重新包装下,再次推向市场,看看能不能掀起一点波澜。
还有一点就是,上面的空白字符中文对齐方法在IE6下不能完全兼容,而当年11年的时候,IE6在中国还是很嚣张的,所以,很多小伙伴后来就没坚持。而如今,大红灯笼高高挂,IE6早早休掉回娘家,没有了阻碍,此方法说不定能掀起一点波澜。
二、空格新成员 
「叉三千」指什么呢?哈哈,其实是全角空格。
中文字体都是等宽的,一个全角空格的宽度就是一个普通中文的宽度。所以,上面的demo中 空格换成全角空格也是可以滴!
但是,我们不能直接在页面中打全角空格,因为在大多数编辑器中空格是透明滴,很容易就被删掉;另外,HTML压缩时候,空格很可能被干掉!咋办?需要转换书写形式。
在web页面上,一般有3种书写:
- 直接,例如搜狗输入法输入“版权” –
©. - web字符,
© - charCode表示:
©
而上面的 ,  就是具有特定名称的web字符。但是,恕我寡闻,我并不清楚全角空格是否有对应& + 关键字示意,所以,就使用工具转成了charCode字符表示,也就是这里的 ,又称「叉三千」!
稍等,你刚说了工具,什么工具!?
哈,这位同学好敏锐,我是有一个私藏的小工具,可以把任意字符转换成HTML识别格式,若有兴趣,您可以狠狠地点击这里:任意字符转换成HTML识别格式工具页面

使用了这个工具,你会发现 ,  原来是相邻兄弟关系:
 →  → 
三、更多内容
当中文和英文混杂的时候,使用 ,  等空格实现冒号的完美对齐还是有些困难的,除非英文使用的是等宽字体,于是乎,我们就可以使用普通的 空格做英文字符的宽度调节。
再科普点关于字符的实用知识吧:
1. HTML中字符输出使用&#x配上charCode值;
2. 在JavaScript文件中为防止乱码转义,则是\u配上charCode值;
3. 而在CSS文件中,如CSS伪元素的content属性,直接使用\配上charCode值。
因此,想在HTML/JS/CSS中转义“我”这个汉字,分别是:
我\u6211, 如console.log('\u6211');\6211, 如.xxx:before { content: '\6211'; }
考虑到直接 这种形式暴露在HTML中,可能会让屏幕阅读器等辅助设备读取,从而影响正常阅读流,因此,我们可以进一步优化下,使用标签,利用伪元素,例如:
.half:before { content: '\2002'; speak: none; }
.full:before { content: '\2003'; speak: none; }
这样,占位的空格字符即不能读,也不能选了。您可以狠狠地点击这里:伪元素生成空格与中文字符对齐demo

好了,就这些,放水完毕!

本文为原创文章,会经常更新知识点以及修正一些错误,因此转载请保留原出处,方便溯源,避免陈旧错误知识的误导,同时有更好的阅读体验。
本文地址:http://www.zhangxinxu.com/wordpress/?p=4562
(本篇完)
- web页面相关的一些常见可用字符介绍 (0.741)
- 小tip:中文英文左右padding一致两端对齐实现 (0.333)
- checkbox复选框的一些深入研究与理解 (0.302)
- CSS vertical-align的深入理解(二)之text-top篇 (0.302)
- absolute元素在text-align属性下的对齐显示 (0.302)
- 好消息,align-content垂直居中也适用普通元素啦 (0.302)
- 高富帅seajs使用示例及spm合并压缩工具露脸 (0.259)
- SVG精简压缩工具svgo简介和初体验 (0.259)
- 基于active,checked等状态类名的web前端交互开发 (0.259)
- 瞎折腾:把JS,CSS任意文本文件加密成一张图片 (0.259)
- 小卖弄:开心网标签词观点交互的CSS实现 (RANDOM - 0.107)

 我的应用
我的应用 我的应用
我的应用{kind=link}
我做合同模板有类似的对齐需求,验证过博主的x3000方式,兼容性有些欠缺,不过也算一种思路,我又回归到用标签来定义一个字符的宽度(width:1em;)了
被你成为恶魔,差点就放弃使用这个恶魔了,翻译太重要了
& emsp; 打不出来
行家啊,&#x、\u、\ 又学了一招。
发现一个有趣的问题,在苹果的”Helvetica Neue”, Helvetica, 这两种字体下 所占的空间比正常的中文字符短→_→
中英文混合的时候,用来试了一下,有些可以对齐,虽然只能凑凑,有些还是有偏差
大哥,ios上对不齐啊
今天刚碰上,可以检查一下字体支不支持中文
鑫爷还是一如既往的牛逼/qiang
不错哟
学到了,真心不错,只是上海人都有这种特质吗?精打细算,很佩服,不成功都怪事。
每个li之间的垂直距离,我用line-height:ex em;设置,你用的什么?
还有那个防止辅助阅读器ex设备读取的句子中before是啥子意思?
呵呵!有点刨根问底,还请不吝赐教。
惨不忍睹。
本文从头至尾全都是错的。
你数年前的理解就是错的,这么久以来不但没有发现错误并寻求改正,反而试图重新包装,用彻头彻尾反工程的思路解决问题,简直不可救药。
nbsp 是 non-breaking space,其意义在于,空格前后的单词即使位于行尾,换行时也不会从空格处截断。一般用于人名、书本章节(Vol. 1, Chapter 2)等地方,保证其作为一个整体。这其实是针对数字排版领域引入的新问题(介质不固定)提出的解决方案。nbsp 也绝对不是所谓「按下 space 时输入的普通空格」,它也不是需要你常用的工具,否则你写文章根本就无从换行。nbsp 是一定要手动转义使用的。
ensp 和 emsp 只是取排字常用单位 en 与 em 而已,thinsp 也只是顾名思义的事。这当中向来没有「学名不详」之说。
这些都不讲,重点在于,数字排版领域,用空格对齐中文,本来就是错误的做法。超过四字怎么办?写好的代码你又怎么维护?再说,你能保证用空格就能对齐?引入容器标签就是浪费,用空白 span 代替手工插入空格还成了小 tip?放着好端端的 justify 不用来研究这种歪门邪道 dirty hack,简直莫名其妙。
使用 HTML Entity 可以保证编码兼容与可读性,除非是没有覆盖到的字符,否则用 charCode 意义何在?对着四位数字发愣?
无论是自己存档还是撰文分享,起码要保证内容是正确、合理的。沉迷于一知半解与雕虫小技,巩固自己的无知偏见还沾沾自喜,简直愚不可及。
不知道你没有在各个浏览器上试,如果没试,就来乱说一气,那才是误导别人,在某些主流浏览器上,不加空格,实在不知道你是怎么只用justify做到对齐的,如果你有不加空,就能在各个流览器上只用justify做到两端对齐,麻烦贴下代码,也让我们都来学习一下,顺便为你的结论做个有力的证明
http://jsfiddle.net/yukirock/a2eaaktq/
这demo写的,从来没有做过兼容性吧
我去,你是逗比吗,我还满心欢喜的去测试了一下,里面那个justify-content不能直接用于文字,你这个例子里还用js把每个文字外面包裹了一层div,对齐个文字还要用js,而且一个文字增加个标签,而且说得那么厉害的样子,,你也是个人才
我以为yukirock大侠是有着多么niubility的真知灼见才敢这样全盘否认他人提出的见解,这种对不同声音深恶痛疾的坚决态度也使我非常想得知下文如何,今天看到了yukirock大侠给出的justify排版对齐方案,果然如意料中的失望:一个简单的中文排版,JS都用上了,而且一上来就是for循环,说好的性能呢?为每个中文文字都包裹一个div标签,这HTML结构也是醉了;这些都不讲,重点在于,这种方式的兼容性只限于现代浏览器,IE8都敢不兼容?
话说回来,我感觉博主的这种空格对齐法思路还是蛮不错的,当然兼容性方面还是不够完美,Safari浏览器下&ensp;和&emsp;都会显示为乱码,但整体要比yukirock的方法更好。
跪了,自己还说引入标签浪费,你这还有js去动态创建div标签去包裹文字,性能呢?js加载慢的话dom重新渲染的文字变化的影响呢
@yukirock 误人子弟啊。。。。。。。
专家
哟嗬又来一个只认标准不知道这个世界上的多浏览器兼容复杂性的死脑壳儿
哪来的底气…哪来的怨气…额
然而不能否认 这文章是有错的
至少他为了打脸博主还是做了功课的
最后一行两段对齐有纯CSS解决方案(一搜一把,兼容性难说),空格可以顶到IE6,是200?年网站普遍使用方法。
当然,现在CSS应该是王道了。
至于nbsp,事实标准,许多可视化网页编辑器处理多空格的方式(当然他们都是…)
和 在safari浏览器上不支持
再加一句~\u0028只有在ECMAScript上下文的字符串、正则表达式、标志符中才被当作(
小提示:
手机上慎用,因为很多字符显示不出来。详见:
《部分Android设备内嵌页人民币¥符号显示错误》
http://ons.me/518.html
HTML中实体转义也是分标签的。script\style(他们属于Raw text elements)中的实体不转义~
学习了before 和after如何使用特殊字符。
这个方法不错~~
请问,4字与5字怎么对齐?
例如: 发表评论
请输入密码
这2个怎么对齐?
@男神 只能哭晕在厕所~
可以调整一下描述嘛,“请输入密码”改成“输入密码”,或者“发表评论”改成“请发表评论”
https://developer.mozilla.org/zh-CN/docs/Web/CSS/text-align-last
兼容性警告,如果你在2015年。
我习惯使用全角中文空格来处理,代码是: 怕浏览器解析了再加空格发一次:&# 12288;
轻松涨姿势
高能啊
用过但忘记了。
letter-spacing也有用过
沙发,哈哈
我一般都是直接输入全角or半角的空格。
speak:none; 学了一招。