这篇文章发布于 2022年11月30日,星期三,22:21,归类于 JS API, JS实例。 阅读 30429 次, 今日 1 次 10 条评论
by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=10635 鑫空间-鑫生活
本文欢迎分享与聚合,全文转载就不必了,尊重版权,圈子就这么大,若急用可以联系授权。

最近做的某个项目需要大量的DOM节点交互,以前这些API都是临时用用,这一次都是深入实践,感觉完全不一样。
果然,实践才是精深技术最好的方式。
趁着还很温热,感觉总结梳理下。
注:本文章所使用的 API 均不考虑 IE 浏览器,以文本节点处理为主。
一、常见方法
需要了解的基本概念:
文本节点就是纯文字节点,元素节点就是有HTML标签的元素,文本节点和元素节点都属于节点,在文档中使用 Node 表示,元素节点在文档中使用 Element 表示,文本节点则是使用 Text 表示。
1. 创建文本节点
使用 document 对象中的 createTextNode 方法。
例如,创建一个内容是“CSS新世界”的文本节点,则可以:
const textNode = document.createTextNode('CSS新世界');
如果项目不需要兼容IE浏览器,也可以直接使用 Text() 方法进行构造,例如:
const textNode = new Text('CSS新世界');
在某些场景下,也可以使用 cloneNode() 方法以克隆的方式进行创建,例如希望下面的 <span> 元素后面可以再新增“真棒??”这样的字符,可以这么处理:
<span id="span">CSS新世界</span>
const firstChild = span.firstChild; const appendNode = firstChild.cloneNode(); appendNode.textContent = '真棒??'; firstChild.after(appendNode);
此时,虽然视觉上文字是连续的,实际上代码层面是两个独立的节点:

2. 文本节点的内容读写
文本节点的内容读写可以使用 textContent 属性完成,注意,innerText 是无效的,因为 innerText 是 HTMLElement 方法,不是 Node 方法。
更多区别可参见这篇文章:“JS DOM innerText和textContent的区别”。
使用示意:
span.lastChild.textContent = '确实不错';
对于文本节点,也可以使用 nodeValue 属性返回文本内容。
Node.nodeValue;
然而,有时候,开发人员希望获取的是所有相邻的文本内容,而不是当前文本节点,可以使用 wholeText 属性进行获取。
例如下图的演示效果,上一个案例中的 appendNode 节点分别执行 textContent 和 wholeText 的效果,可以看到,wholeText将 SPAN 元素内所有文本内容都返回了。
.png)
就结果而言,类似于元素执行了 normalize() 方法后的文本值,区别在于,此时的文本节点依然都是独立的节点,而 normalize() 会让所有的文本节点合并为一个。
3. 节点的插入
 外前插使用 before() 方法,外后插使用 after() 方法,内前置使用 prepend() 方法,内后置使用 append() 方法。
外前插使用 before() 方法,外后插使用 after() 方法,内前置使用 prepend() 方法,内后置使用 append() 方法。
相比传统的 insertBefore() 和 appenChild() 方法,上面几个方法支持一次性操作多个元素,这在多节点同时处理的时候非常有用。
举个例子,有如下 HTML 元素内容:
<p id="from"><strong>《CSS新世界》</strong>这本书是真的不错!</p> <div id="to"></div>
希望 #from 元素中的所有节点转移到 #to 元素中,在过去,我们需要使用循环去处理,现在,不需要了,只需要使用 apply 方法,将 NodeList 作为参数传进去就好了,示意如下:
to.append.apply(to, [...from.childNodes]);
PS: 关于上面四个方法,我之前有详细介绍过,可参见“before(),after(),prepend(),append()等新DOM方法简介”一文。
4. 节点的替换
在过去,节点替换都是使用 replaceChild() 方法,语法示意:
parentNode.replaceChild(newChild, oldChild)
如今,只要你的项目不需要兼容 IE 浏览器,就没有任何理由使用此方法的,请使用 replaceWith() 或 replaceChildren() 方法代替,语法更简单更符合直观认知,支持多参数。
Node.replaceWith(node1, node2, /* … ,*/ nodeN); Element.replaceChildren(node1, node2, /* … ,*/ nodeN)
其中,replaceWith 是替换当前元素,replaceChildren 是替换当前元素的所有子元素。
此 API 在后续的案例中会有不太隆重的出场。
5. 节点的分割与合并
 有时候我们希望一个文字节点分成两个不同的文本节点,以便继续之后精细的控制处理,例如替换,装载,删除等。
有时候我们希望一个文字节点分成两个不同的文本节点,以便继续之后精细的控制处理,例如替换,装载,删除等。
此时可以使用 splitText() 方法,语法如下:
newNode = textNode.splitText(offset)
举个例子,有HTML如下:
<style>
.red {
color: red;
}
.blue {
color: blue;
}
</style>
<span class="red">我是红色</span>我是默认色
此时,用户使用鼠标框选了“红色”加后面的“我是”,然后希望设置为蓝色,此时,splitText() 方法就派上用场了。
代码示意(非实际代码,仅考虑理想场景):
const selection = document.getSelection();
if (selection.rangeCount && !selection.collapsed) {
const range = selection.getRangeAt(0);
const startNode = range.startContainer;
const endNode = range.endContainer;
// 分割啦
var eleSet = document.createElement('span');
eleSet.className = 'blue';
eleSet.append(startNode.splitText(range.startOffset));
startNode.after(eleSet);
endNode.splitText(range.endOffset);
eleSet.append(endNode);
}
实操效果如下GIF所示:

合并
如果希望多个独立的文本节点合并为同一个(多文本节点很多时候会增加我们的判断和实现成本),则可以使用 Node.normalize() 方法。
我们打开Chrome浏览器控制台,如果发现HTML元素中的文字都是竖着排列的,而且每行文字外面还有引号,此时就可以使用 Node.normalize() 方法让这些文本节点合体。

6. 节点的上下求索
- 想要获取节点的父级节点,可以使用 Node.parentNode;
- 想要获取节点的父级元素,可以使用 Node.parentElement;
- 想要获取某个祖先元素,可以使用 closest(selector) 方法,参数是该元素匹配的选择器,使用示意:
Node.parentElement.closest('h3, ol, ul'); - 文本节点是没有子节点的,因此 TextNode.childNodes 的长度一定是 0。
.png)
- 元素节点的所有子元素,使用 element.children,所有节点使用 element.childNodes, 返回值都是类数组,不支持 map, some等数组方法,可以使用 Array.from() 方法,或者 […] 语法转为数组。
- 查找某个对应选择器的元素,可以使用 querySelector() 或者 querySelectorAll() 方法,如果是寻找匹配某选择器的子元素,可以辅助 :scope 伪类,例如:
element.querySelector(':scope > .desc')表示匹配第一个类名是 .desc 的子元素。
- 对于第一个子节点,可以使用 element.firstChild 获取,第一个子元素使用 element.firstElementChild;对于最后一个子节点可以使用 element.lastChild 获取,第一个子元素使用 element.lastElementChild;
- 前一个兄弟节点可以使用 Node.previousSibling 获取,如果没有,返回值会是 null,前一个兄弟元素使用 Node.previousElementSibling 获取。
- 后一个兄弟节点可以使用 Node.nextSibling 获取,后一个兄弟元素使用 Node.nextElementSibling 获取。
7. 节点的匹配判断
要判断A节点是否等于B节点,简单点的做法直接 == 判断。
nodeA == nodeB
也可以使用 Node.isSameNode() 方法进行判断:
const isSame = nodeA.isSameNode(nodeB)
如果希望判断两个节点是否一致,所谓一致就是标签一样,属性一样,内容一样,可以使用 Node.isEqualNode 方法。
例如下面的返回值就是 true,虽然 nodeA 和 nodeB 是两个不同的文本节点。
nodeA = new Text('zhangxinxu');
nodeB = document.createTextNode('zhangxinxu');
// 打印内容是 true
console.log(nodeA.isEqualNode(nodeB));
如果节点是元素,且判断其是否匹配某种特性,可以使用 matches 方法进行判断。
例如:
// 是否是 li 标签元素
element.matches('li')
// 是否包含属性 data-id
element.matches('[data-id]')
如果希望判断一个 Node 节点是否在文档中,而不是在内存中(执行 Node.remove() 删除,或者 replaceWidth() 替换后),可以使用 Node.isConnected 判断。
返回 true 则表示在DOM树中,在文档流中。
8. 节点的类型判断
实际开发之中,经常需要判断当前节点是文本类型,还是元素类型。
此时,我都是使用 nodeType 属性进行判断的。
- 如果 node.nodeType == 1,则当前节点是元素;
- 如果 node.nodeType == 3,则当前节点是文本;
nodeType属性值还有其他类型,例如评论、文档类型等,不过平常用的不多,只需要记住1和3这两个值就可以了。
如果1和3总是记不住,也可以使用Node常量表示。
其中,Node.ELEMENT_NODE表示元素节点,Node.TEXT_NODE表示文本节点。
// 是文本节点
if (node.nodeType == Node.TEXT_NODE) {}
 在有些场景下,我也会使用 nodeName 进行判断,就是当我希望知道某个节点是不是我认为的元素的时候。
在有些场景下,我也会使用 nodeName 进行判断,就是当我希望知道某个节点是不是我认为的元素的时候。
例如,在富文本编辑器中,段落内容的最后一个节点很可能是 <br> 元素,如果是这个元素,类似于文本插入这样的操作就不合适(br标签内的任意内容都不显示),需要特殊处理,此时,使用 nodeName 判断最合适:
if (node.nodeName == 'BR') {
// 特殊处理
}
和 tagName 属性的区别在于,tagName 只有元素节点才有,文本节点调用 tagName 属性返回的是 undefined,而调用 nodeName 返回的就是 ‘#text’。
9. 节点的位置比较
这个我也用到了,使用的是 compareDocumentPosition 这个 API,之前有深入介绍过,参见“深入Node.compareDocumentPosition API”一文,这里不再赘述。
.png)
二、常见案例
虽然节点相关的属性和方法很多,但依然无法满足所有的场景需求,需要配合语言层面的语法实现。
这里展示若干个我项目中用到的处理场景,如果你也有类似需求,直接复制代码即可,别客气。
下面所有案例效果,您均可以狠狠地点击这里体验:文本节点交互处理合集demo
1. 最祖先的匹配元素
Element.closest() 方法虽然也可以向上匹配,但是匹配的是最近的祖先元素,如果我想匹配最远的祖先元素呢?
那就得递归寻找了。
Element.prototype.farthest = function (selector) {
if (typeof selector != 'string') {
return null;
}
let eleMatch = this.closest(selector);
let eleReturn = null;
while (eleMatch) {
eleReturn = eleMatch;
eleMatch = eleMatch.parentElement.closest(selector);
}
return eleReturn;
};
使用示意,已知 HTML 如下:
<div id="a">
<div id="b">
<button id="button">点击我</button>
</div>
</div>
则 button.farthest('div').id 的返回是就是 ‘a’,是最外层那个 DIV 元素的 id 属性值。
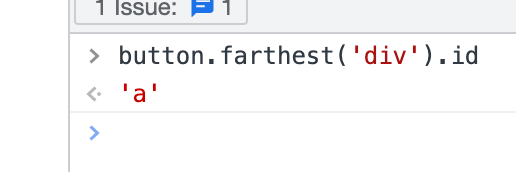
2. 最深的首(尾)节点(元素)
我们有时候需要知道某个元素最深的尾节点,或者尾元素,比方说想要知道把光标聚焦的位置是不是最后一个子元素的时候。
以下就是代码实现示意,对于文本节点,特意过滤了空白节点,如果你希望空白文本节点也被采纳,过滤对应的 if 处理语句即可!
节点获取的JS代码:
Object.defineProperties(Node.prototype, {
// 获取最深的第一个节点
// 过滤空白节点
firstNode: {
get: function () {
if (!this.childNodes.length) {
return null;
}
let nodeReturn = null;
const step = function (node) {
let nodeMatch = node.firstChild;
// 空白节点不处理
if (nodeMatch && nodeMatch.nodeType == 3 && nodeMatch.nodeValue.trimStart() == '') {
nodeMatch = nodeMatch.nextSibling;
}
if (nodeMatch) {
nodeReturn = nodeMatch;
step(nodeMatch);
}
}
step(this);
return nodeReturn;
}
},
lastNode: {
get: function () {
if (!this.childNodes.length) {
return null;
}
let nodeReturn = null;
const step = function (node) {
let nodeMatch = node.lastChild;
// 空白节点不处理
if (nodeMatch && nodeMatch.nodeType == 3 && nodeMatch.nodeValue.trimEnd() == '') {
nodeMatch = nodeMatch.previousSibling;
}
if (nodeMatch) {
nodeReturn = nodeMatch;
step(nodeMatch);
}
}
step(this);
return nodeReturn;
}
}
});
元素获取的JS代码:
Object.defineProperties(Element.prototype, {
// 获取最深的第一个元素
firstElement: {
get: function () {
if (!this.children.length) {
return null;
}
let eleMatch = this.firstElementChild;
let eleReturn = null;
while (eleMatch) {
eleReturn = eleMatch;
eleMatch = eleMatch.firstElementChild;
}
return eleReturn;
}
},
lastElement: {
// 获取最深的最后一个元素
get: function () {
if (!this.children.length) {
return null;
}
let eleMatch = this.lastElementChild;
let eleReturn = null;
while (eleMatch) {
eleReturn = eleMatch;
eleMatch = eleMatch.lastElementChild;
}
return eleReturn;
}
}
});
语法:
element.firstNode; element.lastNode; element.firstElement; element.lastElement;
如果没有对应的节点元素,返回的是 null。
3. 获取所有文本节点
 有时候我们希望指定元素内的所有文本节点,方法很多,我个人觉得比较好的实现是使用节点迭代器 createNodeIterator() 方法。
有时候我们希望指定元素内的所有文本节点,方法很多,我个人觉得比较好的实现是使用节点迭代器 createNodeIterator() 方法。
实现代码:
// 获取所有的文本节点
Object.defineProperty(Element.prototype, 'childTextNodes', {
get: function () {
// 获取所有的文本节点
const nodeIterator = document.createNodeIterator(this, NodeFilter.SHOW_TEXT, (node) => {
return node.textContent.trim() ? NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_REJECT;
});
// 节点迭代器转为数组并返回
const arrNodes = [];
let node = nodeIterator.nextNode();
while (node) {
arrNodes.push(node);
node = nodeIterator.nextNode();
}
return arrNodes;
}
});
语法:
const arrTextNode = element.childTextNodes;
当前DOM元素调用属性 childTextNodes,会返回一个包含所有文本节点的数组,如果没有匹配的项目,返回的是空数组。
4. 获取选区内所有节点
用户在页面上跨选了一段文字,希望知道这部分选区都包含了哪些节点元素,可以试试下面的代码:
const getNodesInRange = function (range) {
var start = range.startContainer;
var end = range.endContainer;
var commonAncestor = range.commonAncestorContainer;
var nodes = [];
var node;
// 使用公用的祖先进行节点遍历
for (node = start.parentNode; node; node = node.parentNode) {
nodes.push(node);
if (node == commonAncestor) {
break;
}
}
nodes.reverse();
const getNextNode = function (node) {
if (node.firstChild) {
return node.firstChild;
}
while (node) {
if (node.nextSibling) {
return node.nextSibling;
}
node = node.parentNode;
}
}
// 遍历子元素和兄弟元素
for (node = start; node; node = getNextNode(node)) {
nodes.push(node);
if (node == end) {
break;
}
}
return nodes;
}
如果希望只返回文本节点,可以再过滤下,JavaScript 代码示意:
// 获取选区内的所有文本节点
const getTextNodesInRange = function (range) {
return getNodesInRange(range).filter(node => node.nodeType == 3 && node.textContent.trim());
};
其中,参数 range 就是当前页面(获取方法见下面代码示意),或者自己创建(使用 document.createRange() 方法)的选区。
// 返回当前页面 range 常用方法 const range = document.getSelection().getRangeAt(0);
下面是demo页面的使用示意代码,当点击抬起的时候,会输出当前选区所包含的所有文本节点内容:
// 选区内文本节点显示
document.addEventListener('mouseup', function () {
const selection = document.getSelection();
output.innerHTML = getTextNodesInRange(selection.getRangeAt(0))
.map(node => node.textContent)
.join('');
});
5. 元素TAG标签变化
举个例子,有段文字是使用 <b> 元素加粗的,现在希望统一为 <strong> 元素,请问该怎么处理?
<!-- 请把 b 换成 strong 但不影响里面的节点 --> <b>钓鱼可否?<a href="https://item.jd.com/13356308.html">《CSS新世界》</a></b>
此时就需要 replaceWidth 和 append 方法出马了,下面是我的实现,让元素的 tagName 属性变得可写。
// 改变元素的标签方法
const propsTagName= Object.getOwnPropertyDescriptor(Element.prototype, 'tagName');
Object.defineProperty(Element.prototype, 'tagName', {
...propsTagName,
set: function (name) {
if (typeof name != 'string' || name.toUpperCase() == this.tagName) {
return;
}
const eleNew = document.createElement(name.toLowerCase());
eleNew.append.apply(eleNew, [...this.childNodes]);
this.replaceWith(eleNew);
return name;
}
});
此时,任意元素执行下面的语法,就可以改变自身的标签了。
element.tagName = 'newTagName'
需要注意的是,当此语句执行后,element对象就不在文档中了,而是在内存中,如果你继续做一些DOM处理(如获取父元素),结果会是 null。
下图是demo页面交互操作后的GIF录屏示意,可以看到元素的标签从b转为strong了:

6. 部分文字变成 HTML 元素
 有时候,我们希望一段文字中的某几个字变成 HTML 元素,有一种简单的方法就是 innerHTML 直接正则替换。
有时候,我们希望一段文字中的某几个字变成 HTML 元素,有一种简单的方法就是 innerHTML 直接正则替换。
但,如果这段文字中的某个 HTML 元素绑定了事件,或者光标正在在这段文字中,这么处理就会丢失事件,或者丢失光标。
有一种低侵入的实现方法,就是借助 Range 选区对象的 surroundContents 方法。
代码示意:
// 部分文字使用 HTML 包装
// selector 表示希望包裹的HTML元素选择器
// 仅支持标签和类名选择器
// text 表示希望包裹的字符,不设置表示整个文本节点
Text.prototype.surround = function (selector, text) {
const textContent = this.nodeValue;
if (!textContent || !selector) {
return null;
}
text = text || textContent;
// 包装的元素标签和类名
const arrClass = selector.split('.');
const tagName = arrClass[0] || 'span';
const className = arrClass.slice(1).join(' ');
// 索引范围
const startIndex = textContent.indexOf(text);
if (startIndex == -1) {
return null;
}
const range = document.createRange();
range.setStart(this, startIndex);
range.setEnd(this, startIndex + text.length);
// 元素创建
const eleSurround = document.createElement(tagName);
if (className) {
eleSurround.className = className;
}
// 执行最后一击
range.surroundContents(eleSurround);
return eleSurround;
};
假设有 HTML 代码如下:
<p id="wrap">保佑今天钓鱼爆护!</p>
我们希望“钓鱼”两个字加粗,则一句话的事情:
wrap.firstChild.surround('strong', '钓鱼');
此时该元素的 outerHTML 字符内容为:
<p id="wrap">保佑今天<strong>钓鱼</strong>爆护!</p>

7. 相同状态元素的合并
有时候为了让我们的 HTML 代码更加干净,需要对标签进行合并,以方便后续的处理。
例如下面的HTML有两个连续的 <strong> 元素,其实可以合二为一。
保佑今天<strong>钓鱼</strong><strong>爆护</strong>!
又比如在编辑器中的连续两个 ol 有序列表,其实应该合并为一个。
下面就是自己的实现代码:
// 合并等同元素
Element.prototype.merge = function (selector) {
if (!selector) {
return;
}
[...this.querySelectorAll(selector)].some(ele => {
// 如果和前面的节点类型一致,合并
let nodePrev = ele.previousSibling;
let elePrev = ele.previousElementSibling;
if (!nodePrev || !elePrev) {
return false;
}
// 非内联元素换行符忽略
const display = getComputedStyle(ele).display;
if (nodePrev.nodeType == 3 && (nodePrev.nodeValue === '' || (!/inline/.test(display) && !nodePrev.nodeValue.trim()))) {
nodePrev.remove();
// 递归处理
this.merge(selector);
return true;
}
// 如果前面的节点也是元素,同时类名一致
if (nodePrev && nodePrev == elePrev && ele.cloneNode().isEqualNode(nodePrev.cloneNode())) {
elePrev.append.apply(elePrev, [...ele.childNodes]);
ele.remove();
// 递归处理
this.merge(selector);
return true;
}
});
};
语法如下:
element.merge(selector);
此时,element元素中匹配选择器 selector 的相邻两个类似(标签和属性一样)的元素会合二为一。
例如:
document.body.merge('ol');
会让页面中两个相邻的有序列表合二为一。

眼见为实,以上所有案例均可以访问此页面进行体验。
三、打道回府
好了,就暂时这么多。
实际开发中,肯定还有很多其他与文本节点相关的需求。
如果您有遇到,且自己又不会写的,评论留言,我会把代码写给你,放心,我现在可是文本节点处理大师。

本文为原创文章,欢迎分享,勿全文转载,如果实在喜欢,可收藏,永不过期,且会及时更新知识点及修正错误,阅读体验也更好。
本文地址:https://www.zhangxinxu.com/wordpress/?p=10635
(本篇完)
- before(),after(),prepend(),append()等新DOM方法简介 (0.346)
- 见多识广,介绍Web开发中current开头的一些API属性 (0.231)
- 巧用DOM API实现HTML字符的转义和反转义 (0.138)
- 深入Node.compareDocumentPosition API (0.123)
- JavaScript实现新浪微博文字放大显示动画效果 (0.092)
- 小tip: DOM appendHTML实现及insertAdjacentHTML (0.092)
- 盘点HTML字符串转DOM的各种方法及细节 (0.092)
- JS原生的深拷贝API structuredClone函数简介 (0.092)
- jquery之append与insertBefore使用实例 (0.069)
- 利用剪切板JS API优化输入框的粘贴体验 (0.069)
- gitee上撸了个类似飞书OKR输入框的@提及项目 (RANDOM - 0.069)

 我的应用
我的应用 我的应用
我的应用{kind=link}
实在抱歉,评文无关,但是侧边栏的那个自动播放广告真的好烦人……
虽然敬佩大师的水平,无论如何,日后如果入这行也会买那部书的……
以前不自动播放的,最近不知道怎么了,我研究下
5. 节点的分割与合并
这里如果红色部分是下划线,改蓝色时候,如果也能保留下划线就完美了
好评
第一个文字连续两个text node 可以给父节点normalize就合并了
希望大佬出一篇关于打印的全攻略??
想起微信读书那个每个字都是绝对定位的页面
感觉在做富文本编辑器啊
哈哈哈 配的这些图片好搞笑
tql