这篇文章发布于 2018年03月27日,星期二,23:02,归类于 JS实例。 阅读 66174 次, 今日 7 次 13 条评论
by zhangxinxu from http://www.zhangxinxu.com/wordpress/?p=7463
本文可全文转载,但需得到原作者书面许可,同时保留原作者和出处,摘要引流则随意。
一、何为文本类文件?
所谓文本类文件,指MIME Type为text/*文件,例如,CSS文件(text/stylesheet),JS文件(text/javascript),HTML文件(text/html),txt文本(text/plain)等等。
在现代浏览器下,我们可以直接对这些文件进行处理,无论是通过type=file表单元素还是从桌面拖拽到网页中都是可以的。
二、纯前端JS读取与解析本地文本类文件
已知file就是文件对象,则核心CSS如下:
var reader = new FileReader();
reader.onload = function (event) {
// event.target.result就是文件文本内容
// 然后你就可以为所欲为了
// 例如如果是JSON数据可以解析
// 如果是HTML数据,可以直接插入到页面中
// 甚至字幕文件,各种滤镜,自定义文件格式,都可以玩弄于鼓掌之间……
};
reader.readAsText(file);
核心就是readAsText()这个方法,我们可能有用过的前端预览本地图片,则用的是FileReader.readAsDataURL()方法,一个转文本,一个转base64,性质都是一样的。
目前file对象通常有下面几种方式获取:
type=file表单元素,假设DOM元素是eleFile,则file对象(假设非多选模式)为eleFile.files[0]。或者也可以在change事件中获取,例如:eleFile.onchange = function (event) { var file = event.target.files[0]; };- 拖拽事件获取。例如:
this.dragDrop.addEventListener("drop", function(event) { var file = event.dataTransfer.files[0]; }, false);
三、实践-实现一个纯前端的简易CSS压缩工具
您可以狠狠地点击这里:CSS在线压缩工具demo
此工具差不多10年了,然后趁此机会加个直接上传CSS压缩功能。操作演示如下:
1. 选择CSS文件,此时会自动触发“开始处理”按钮;
2. 下载CSS文件:
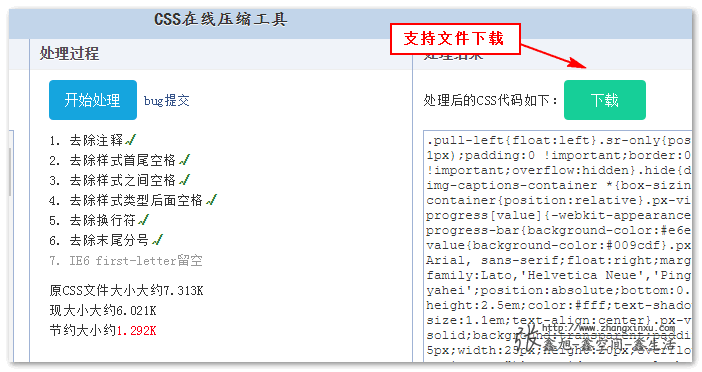
这里的下载功能也是纯前端实现的,有兴趣可以参见之前的文章:“JS前端创建html或json文件并浏览器导出下载”。
相关代码直接右键->查看页面源代码即可!
四、结束语
FileReader对象除了有readAsText()和readAsDataURL()外,还有下面2个标准方法,分别是:FileReader.abort()和FileReader.readAsArrayBuffer().
FileReader.abort()可以终止读操作。
FileReader.readAsArrayBuffer()作用是把Blob或者file对象以ArrayBuffer形式读出来。因此,可以罗列下:
- readAsText() -> 文本字符数据
- readAsDataURL() -> Base64 URL数据
- readAsArrayBuffer() -> ArrayBuffer数据
对于非文本类文件,readAsText()方法也是可以用的,但是读出来的东西……呵呵,怕是用不起来,例如我选一个.docx word文档。结果出来的东西鬼都不认识:
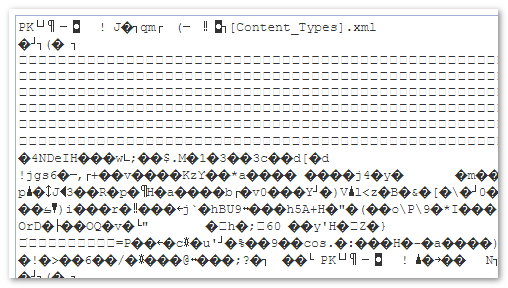
所以,标题中特别标明了文本类文件。
以上~感谢阅读!

本文为原创文章,会经常更新知识点以及修正一些错误,因此转载请保留原出处,方便溯源,避免陈旧错误知识的误导,同时有更好的阅读体验。
本文地址:http://www.zhangxinxu.com/wordpress/?p=7463
(本篇完)
- JS纯前端实现audio音频剪裁剪切复制播放与上传 (0.439)
- 基于HTML5的可预览多图片Ajax上传 (0.253)
- 原来浏览器原生支持JS Base64编码解码 (0.253)
- 基于HTML5 drag/drop模块拖动插入排序删除完整实例 (0.248)
- 拖拽献祭中的黑山羊-DataTransfer对象 (0.248)
- HTML5 file API加canvas实现图片前端JS压缩并上传 (0.195)
- 纯前端实现可传图可字幕台词定制的GIF表情生成器 (0.195)
- 本地MP3封面图、时长等信息的JS读取 (0.195)
- 小tip: base64:URL背景图片与web页面性能优化 (0.186)
- 直接剪切板粘贴上传图片的前端JS实现 (0.142)
- 小tips:使用canvas在前端实现图片水印合成 (RANDOM - 0.068)

 我的应用
我的应用 我的应用
我的应用{kind=link}
文件很大,文件是以 ; 分割,可以只读取 10 条 ;语句吗?
有个问题就是,编码格式,readAsText 默认是utf-8,比如txt 有的读出来是乱码,用 gb2312 格式能解决,但是 这样一来,utf-8 格式读出来 也是乱码,不知道 这个是不是它的硬伤呢,或者前端有什么其他办法可解决吗
那怎么正确显示doc文件,而不乱码
// ▼下载文字为文件的方法
var funDownload = function (content, filename) {
// 字符内容转变成blob地址
var blob = new Blob([content]);
// 创建隐藏的可下载链接
var eleLink = document.createElement(‘a’);
eleLink.download = filename;
eleLink.href = URL.createObjectURL(blob);
eleLink.click(); // 触发点击
// ■■■■■■■■■■■■■■■鑫旭老师好:我发现下面几行代码注释后下载依然有效■■■■■■■■■■■■■■■■■■■■
// eleLink.style.display = ‘none’;
// document.body.appendChild(eleLink);
// document.body.removeChild(eleLink); // 然后移除
};
传说是火狐的bug
我站申请对本章关于前端技术全站转载,用于学习交流,同时保留贵站的版权与出处!我站不会附加任何版权信息!
捉个虫
二节第一行
“已知file就是文件对象,则核心CSS如下:”
最近好高产
可以尝试做照片压缩的
对的,我之前有写过,可以参见这篇文章:“图片前端JS压缩并上传” –
http://www.zhangxinxu.com/wordpress/2017/07/html5-canvas-image-compress-upload/
有个大胆的想法:把word文档拖进浏览器进行编辑…
Google有这功能已经很多年了
文章里说了,word不行 ,word比较特殊